Exploring Cloudflare's Free Tier

Table of contents
- Cloudflare's Free Tier Goes a Long Way
- Let's Build an App!
- Resume Requester
- Building on the Free Tier
- Final Thoughts
Cloudflare's Free Tier Goes a Long Way
With the (somewhat) recent releases of Cloudflare's blob storage and distributed sql products, R2 and D1 respectively, they've amassed quite an arsenal of tools on their free tier. You've got compute in the form of Workers, blob storage through R2, key/value storage in Workers KV, and a sql-lite compliant strongly consistent (with some caveats, more later), globally available database through D1 (still in alpha). With that combination you can build or hack on nearly any idea!
In this post, I'll be building a small application that uses a handful of the offerings in Cloudflare's free tier:
Worth mentioning, is that Cloudflare also offer DNS configuration and CDN services as apart of their free tier. I won't be diving into how they can be used in this series - but they deserve a shout out, I love their DNS configuration tool.
Let's Build an App!
Coming up with a moderately useful idea that runs on the aforementioned technologies was a bit tricky. Ultimately, it came down to either building a simple analytics service or an interactive resume requesting tool. I landed on resume requester as its something I can template and ideally provides value to others.
Resume Requester
One of my favourite sites on the internet has to be Robby Leonardi's interactive resume, it's fun, interactive, informative and demonstrates a lot of his skills. Robby has done a great job of introducing his skills through an interactive and gimmicky experience! Now I'm no fancy designer, so I won't even try to replicate that - but I do like the idea of your personal website being your brand, your portfolio, and the home of your resume.
But... My resume has my private email and my mobile number on it, thats not information that I like to give out willy nilly! So to solve for this I'll build an application on top of Cloudflare's free tier that introduces an "approval" step in the resume requesting process process.
High Level Process
- Someone "requests" my resume
- I get a notification on my phone, giving me two options:
- release the resume
- reject the request
- If released, the requester will receive my email in their inbox
- If rejected, the requester will receive an email politely notifying them of the denial
Architecture
We can look at how the different parts interact in a bit more detail in this architecture diagram below:
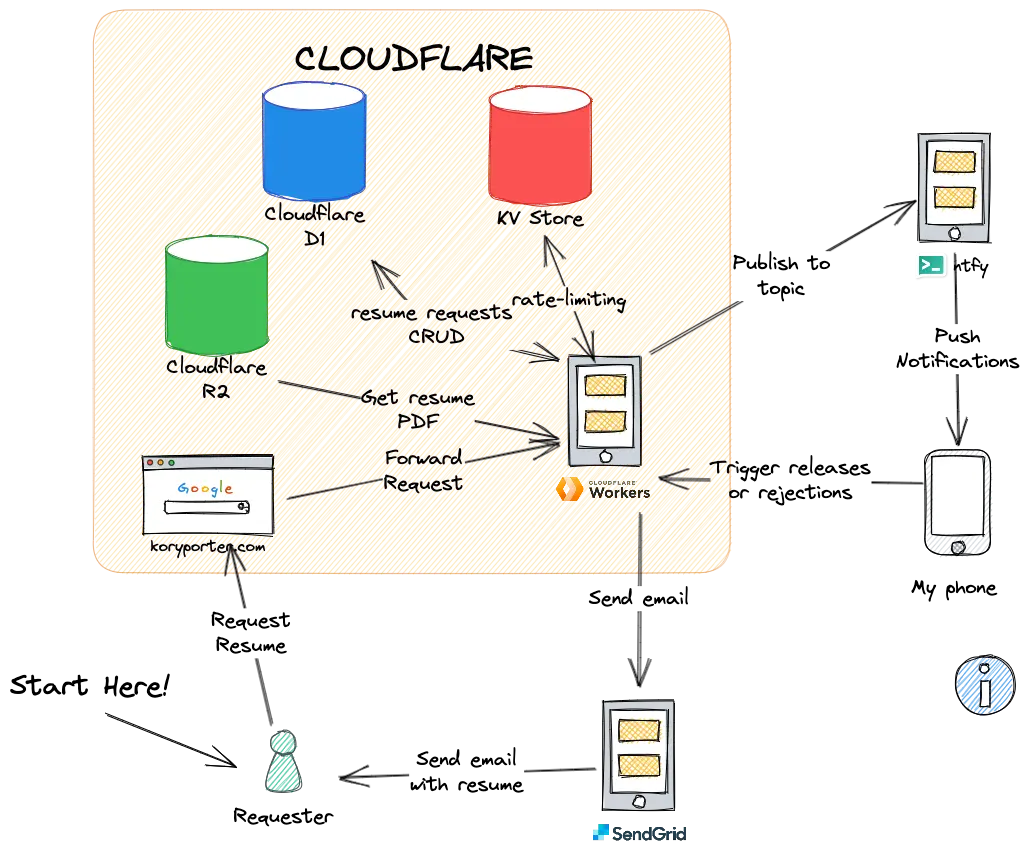
The Cloudflare worker is at the centre of solving this problem, it will interact with:
- D1 -> to write down requests as they come in, and update them as I manually "release" or "reject" the request. Also used as a cache of sorts over the content in R2 (more on the why behind this soon)
- R2 -> to fetch the PDF from blob storage
- KV store -> to do some basic ip rate limiting
- ntfy.sh -> to forward push notifications
- SendGrid -> to forward my resume on to the requester
Final Product
If you'd rather just read the code, the implementation for the application can be found here. I won't be going into detail about how to setup a project on Cloudflare workers, their docs are really good. If you follow this, you can have a worker running on the edge in minutes.
Building on the Free Tier
Before I dive into the different offerings on the free tier, I'd like to call out wrangler, Cloudflare's CLI for all thing developer(y)! The ease of deployment, development, and configuration thanks to Wrangler is possibly the best I've seen or used to date in my career. It's insanely quick, easy to use, and has clear error messages. Wrangler enables you to spin up workers, setup a dev environment, add secrets, spin up instances of D1, etc.
Pages
Pages are a no bullshit product by Cloudflare, at its simplest all you do is point it at a git repository, tell it what type of frontend application it is (react, vue, next, etc.), and on each push to the origin, it'll build and deploy your frontend to a public domain backed by SSL. If you push to a branch that isn't main, it'll build and deploy the frontend application to a preview url.
Moving on from the simplest path, Pages offer the ability to deploy serverless functions that your frontend can interact with. Pretty much just workers, but from within the same codebase. These contribute to the free tier limits of Cloudflare workers, quite generously at 100,000 invocations as of right now (2023/01/31).
https://koryporter.com is hosted on Cloudflare Pages. I connected the git repo for this website, followed the UI prompts and when asked what type of frontend I am deploying, I selected Next.js static site, and it did the rest! Only change I've made was wiring up a custom domain to the pages deployment. https://koryporter.com is a CNAME pointing to the pages deployment origin.
Workers
Workers are just serverless compute... but on the edge. Ok that was a bit reductive, but its mostly true. I say mostly because I believe they differ in two key areas:
- custom runtime, and
- the tooling (wrangler)
I'll expand on the custom runtime shortly.
It's pretty common to for serverless providers to be prescriptive in how you structure the entrypoint to your application. E.g, you need to have a file named x, with a function named y inside it as your entry point. So seeing the following which closely mirrors the cloudflare getting started docs, wasn't a massive surprise:
export default {
async fetch(
request: Request,
env: Env,
ctx: ExecutionContext
): Promise<Response> {
return new Response("G'day friend!", { status: 200 });
},
};
What was a surprise was that the function name fetch isn't completely arbitrary. Cloudflare workers are based, at least partly so, on the Web Workers API. Which means you get everything in the WorkerGlobalScope available to you. So when your worker gets lit up, a FetchEvent is passed directly to your fetch handler! More on this here. You could also represent the above in standard JS Service Workers syntax:
addEventListener("fetch", (event) => {
event.respondWith(handleRequest(event.request));
});
async function handleRequest(request) {
return new Response("G'day friend!", { status: 200 });
}
I mentioned earlier that the runtime is what differentiates Cloudflare from many of the other serverless providers. One of the reasons Cloudflare can bill based on CPU cycles, and also the reason why there is no cold starts - is that each Worker runs on a V8 isolate, they are essentially little sandboxes that run within a single v8 runtime. This means your worker code, and a complete strangers worker code, can be running along side each other in the same v8 process, on the same host! A V8 runtime switches between many (hundreds, thousands) isolates constantly, and memory between isolates is not shared (isolated 🤠). A fantastic explanation, with graphics explaining the concept can be found here on the Cloudflare website.
KV
I have an irrational fear of releasing anything that relies on compute in the public, without first having some form of rate limiting. I'm not sure how deep we want to analyse this - but it likely comes back to those invasive thoughts that most engineers get when their friend says "oh yeah, it's pretty solid, you couldn't bring it down" - "hehe, watch me"! Well to try and protect this service somewhat from bad actors (and also an excuse to use both KV and D1 in the same project) I introduced some rate-limiting.
KV is an eventually consistent global data store. This means you aren't guaranteed access to the latest data for a key on read. Writes aren't distributed, nor are they broadcasted after the event, they go to the central data centre which could be in an entirely different region to the edge. As I said, writes aren't broadcasted after they've been written, if you request a value from KV and its previous value is already cached on the edge, you'll be left waiting potentially up to 60 seconds for that value to expire until you are able to fetch and consume the fresh value.
Another alternative to solve this problem would be to use Durable Objects (link). Durable objects support (not sure if they guarantee) atomic writes and reads, so you're less likely to get stale data on a read after a write. Durable Objects are no on the free tier though, you need to upgrade to a paid plan to get access to them.
The eventually consistent nature of KV store isn't really a problem for my use case, I don't need overly accurate rate limits.
Nothing really interesting to report on dev interaction side of KV, it... gets keys, and sets values... The free tier is set at 100,000 reads, and 1,000 writes. Workers KV also ships with the ability to set a TTL on values, which opens it up to more use cases (like time bound caching).
It's as simple as:
// reading
const ipHits = await env.KV.get(`limit:${ip}`);
// writing (with a TTL)
await env.KV.put(`limit:${ip}`, `${hits + 1}`, { expirationTtl: 10 * 60 });
R2
If you have used a form of blob/object storage before (AWS S3, GCP Cloud Storage, Azure Blob Storage), then R2 won't come as a shock to you. It stores unstructured data. One differentiator between R2 and it's competitors like S3 or Cloud Storage, is that it doesn't charge on data egress. The pricing model is based around storage size, and api requests, not ingress or egress!
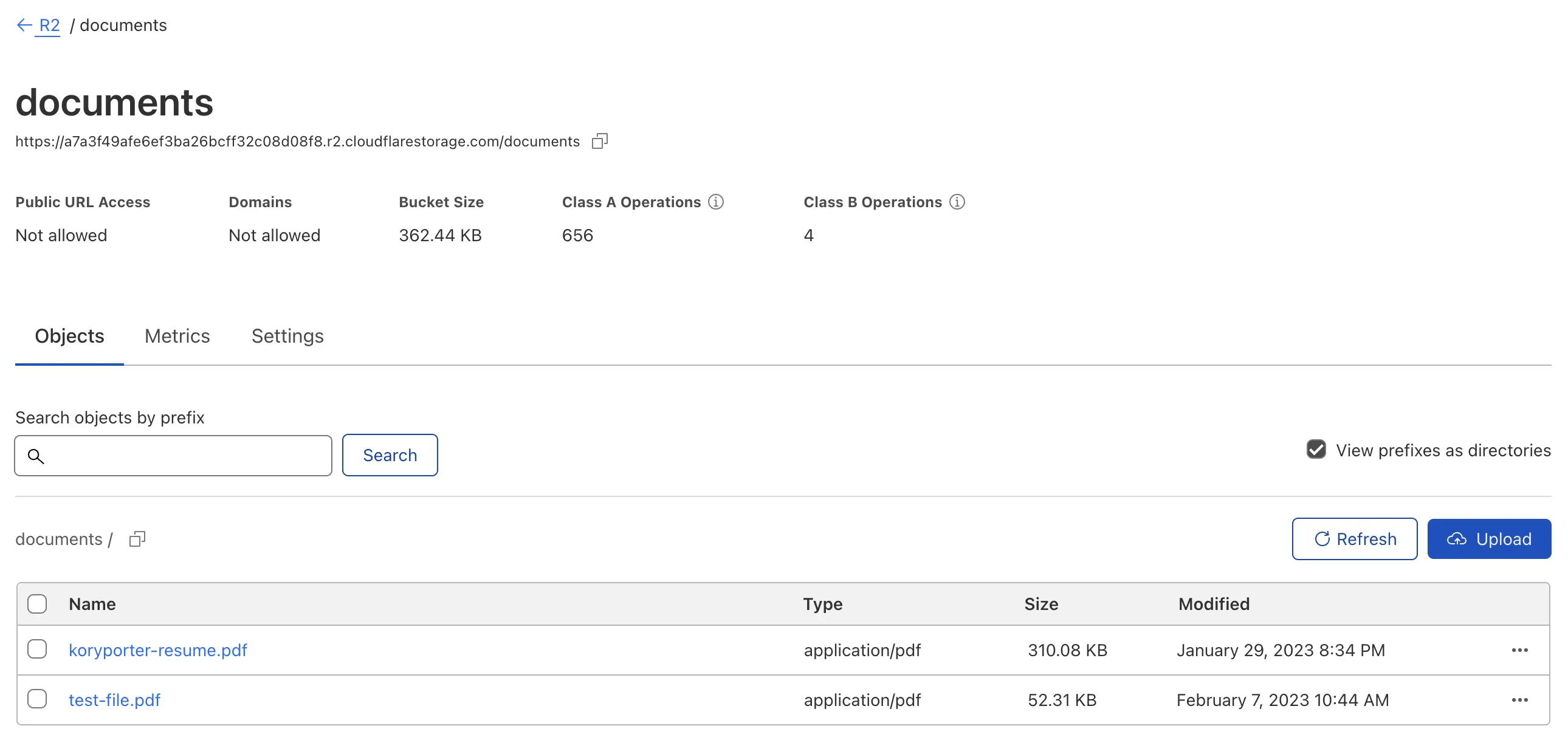
My use of R2 was very simple in this project, I used it to list documents, and read documents. I go into more detail on my usage of R2 with D1 below.
D1
I started this article by saying D1 was a "sql-lite compliant strongly consistent (with some caveats, more later), globally available database". This is all true at a certain point in time, but when read replicas are created, D1 is no strongly consistent. When Cloudflare announced D1 (source: Announcing D1, they mentioned that D1 is built on top of Durable Objects, which guarantees strong consistency, no matter where the object is accessed from in the world. So I assume, for the most part they get the "strong" part of consistency from Durable Objects, but that falls apart if you start creating replicas - there will naturally be some lag propagating the change from the master back to the slaves/replicas. There isn't a lot of information around this behaviour yet, it's still in alpha.
D1 is still in early alpha, it's really important to note that it's likely most qualms I experienced with D1 are likely to be ironed out before this gets into an RC state.
The main issue I experienced with D1, or more specifically, the combination of D1 with Wrangler, was that you're unable to run a migration against preview database directly. You need to modify your wrangler configuration to add an extra "environment", and then run the migration. But it seems like the Cloudflare team are aware of it.
Another point of contention that only arose once I introduced D1 to the project, was the inability to test scheduled events (CRON triggers for the worker), but again, sounds like its on their radar. This (testing scheduled events) is a really neat feature of the wrangler CLI, so it was a bit of a bummer when it errored out during testing. I should note that D1 + CRON triggers work perfectly -> once the application is deployed. You just can't test it locally - no biggie, it's still in alpha remember!
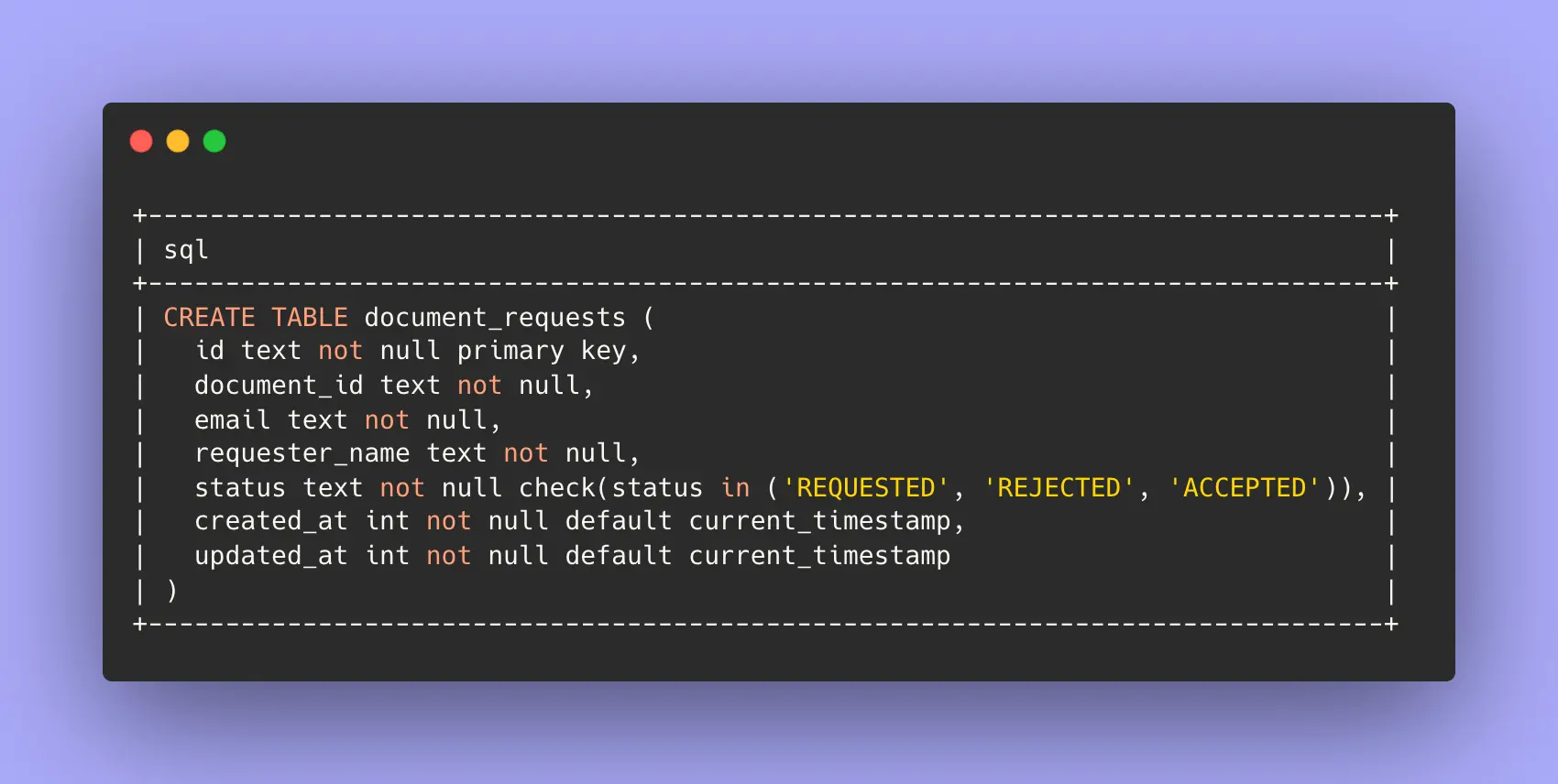
Within the document-requester app I ended up using D1 for two things, the first I'd consider normal usage of a relational data model, and the second a complete hack to ensure I wasn't pushing passed the 10ms CPU time limits of the free tier.
- Storing Requests
- Caching a Base64 content of blobs from R2
Let's dive into those below.
Storing Requests
Nothing of note to report here, I used this table to write down and keep track of state for the requests for my resume. It serves a few purposes:
- writing down requests -> who they're from, and what they're for
- updating requests -> they're either accepted or rejected.
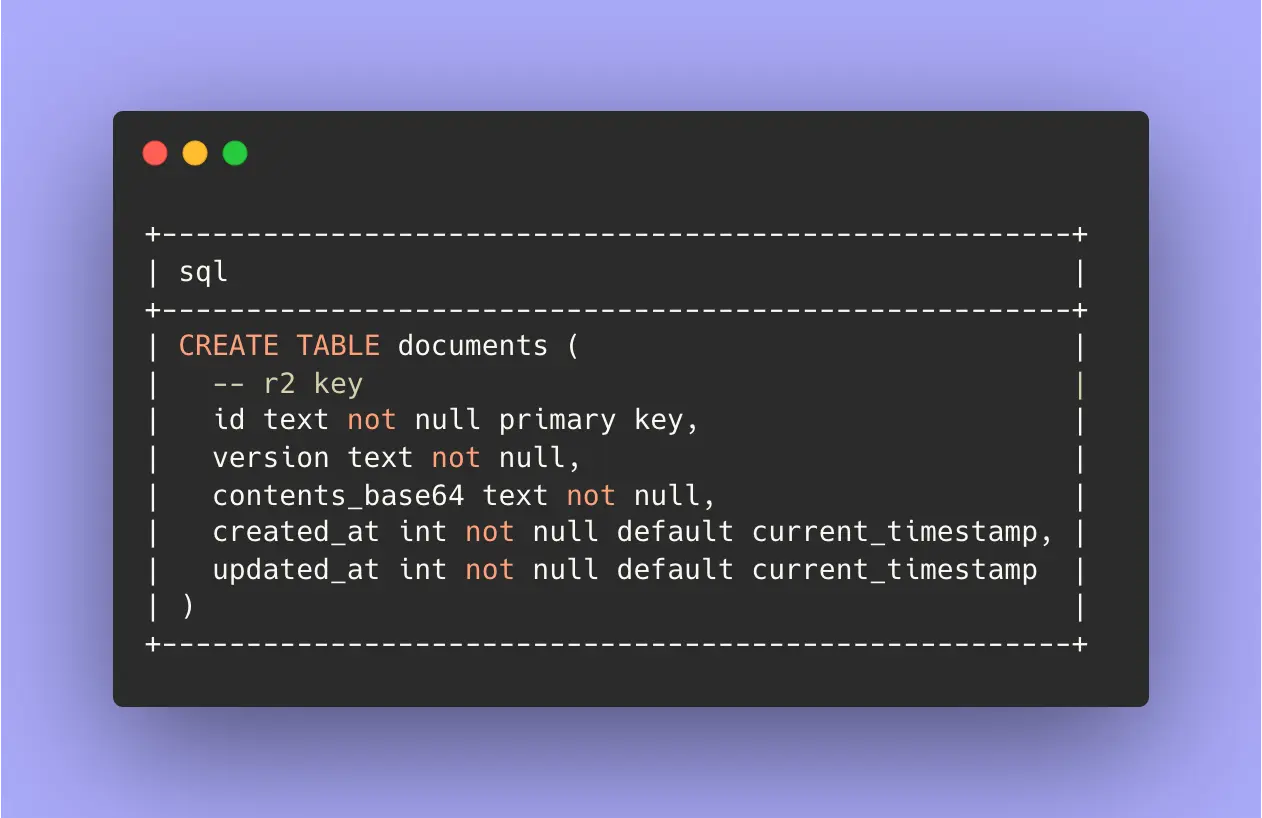
Caching Base64 Copies of R2 Objects
Just as I was wrapping up the implementation of the document-requester project I checked the dashboard in Cloudflare to see how it was performing. I noticed that whenever an email was sent (after accepting/rejecting the request) the average CPU time spiked over 50ms. This is a problem, you're only guaranteed 10ms of CPU time on the free tier, I don't want requests to be dropped. 😱
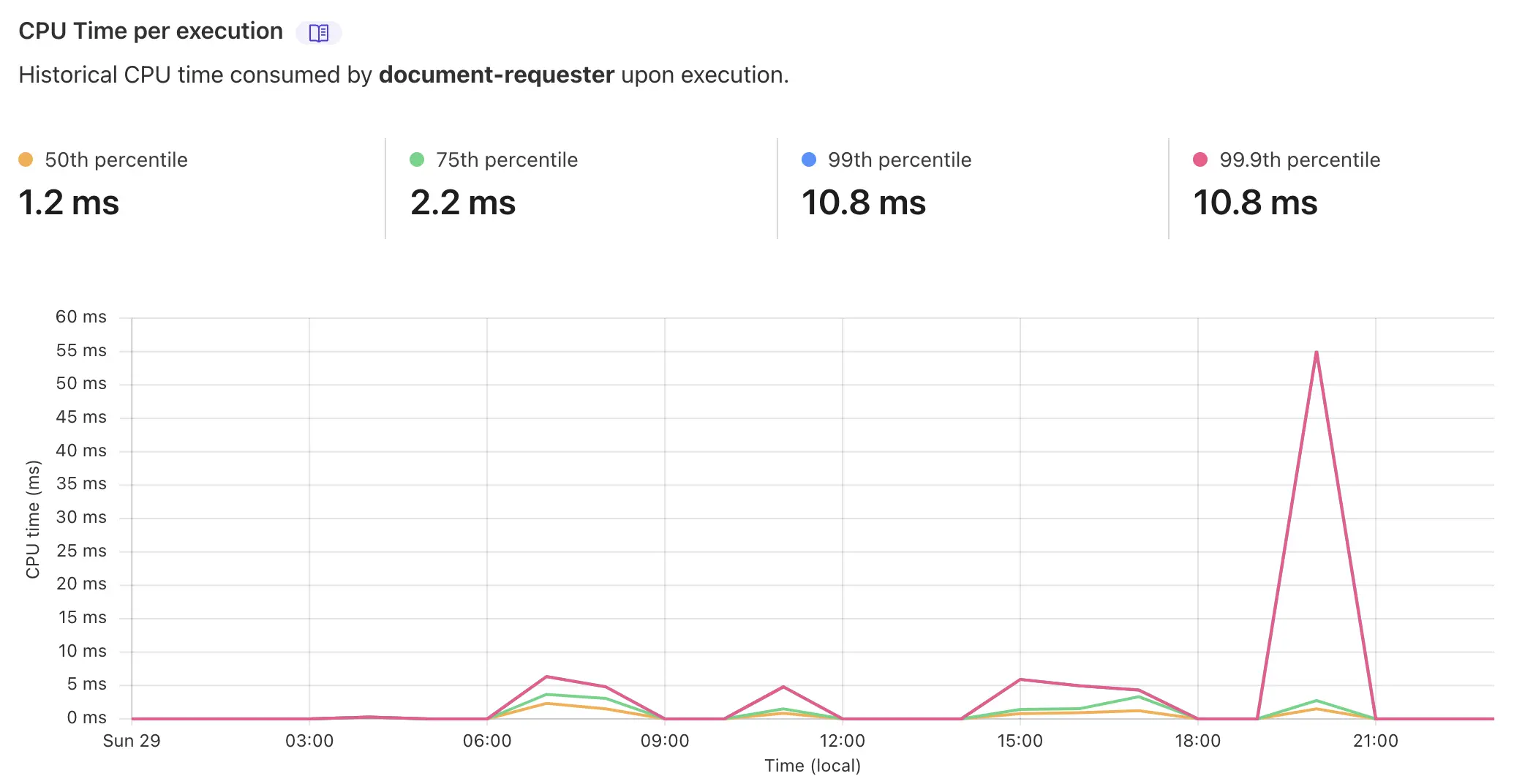
This spike is triggered because of the way SendGrid requires attachments to be formatted. SendGrid expect attachments to be a Base64 representation of a binary file (I wonder if this is a optimisation on their end, or a limitation of email attachments?). So for every document request that gets accepted, I was needing to pull down the file from R2, stream this into an ArrayBuffer, iterate through the buffer byte by byte to populate a string containing the binary, and then finally encode the binary string into a Base64 representation of it self. As you can imagine, all this compute adds up and blows (relative to the free tier limits) the CPU time out to around 50ms (given a 500kb PDF document).
The fact that this request and subsequent requests didn't get dropped was pure luck, if the instance of v8 that this isolate was running on was starved for resources, then theres a good chance these requests would've been a prime candidate to be killed. This is because Cloudflare have a rule on the free tier that you are only guaranteed 10ms of CPU time each invocation, anything above that and your worker can be killed. That's not a strict limit though, given the request above did not fail... I imagine that Cloudflare provide some leniency around bursty workloads. Nevertheless, I took this as an excuse to to have a bit fun - by making this process more fault tolerant.
So, to work around this limitation but still make sure people get the document they requested as an email attachment I decided to instead keep a constantly updated cache of the Base64 representation of ALL files in my documents R2 bucket. I was able to achieve this by using CRON Triggers to periodically check for changes (change being a new file, or a different version of an existing blob) in the bucket, and if there is a change, or if the file is new, then do the above process (fetch, stream, iterate, populate, encode) and then write it down inside of D1, to the documents table.
Now, when I accept a document request the CPU time is down to a median of 0.8ms, there is nearly no compute that needs to occur! 🎊
CRON triggers live right alongside the standard request/response worker code. You just define the entry point slightly different:
export default {
// note that CRON trigger entry-points take a "ScheduledEvent", not a "FetchEvent" like the standard entrypoint for workers!
async scheduled(_event: ScheduledEvent, env: Env, ctx: ExecutionContext) {
async function exec() {
await sync(env);
}
ctx.waitUntil(exec());
},
};
Final Thoughts
I initially found Cloudflare many moons ago when I was looking to replace GoDaddy as my DNS manager for my websites. Cloudflare looked good, had CNAME flattening, and was free. It wasn't long after this when Cloudflare announced Cloudflare Registrar with near wholesale domain name prices, so I started using them as my registrar as well. I very recently revamped my website and the stack it's built on. I went from a Jekyll static site hosted on Netlify, to a NextJS static site which is built and hosted on Cloudflare pages.
I quite enjoyed this expedition on the Cloudflare free tier. I was absolutely blown away with how good the dev tooling is! I don't think it'll be long before Cloudflare is considered part of the "big cloud services providers" and not just a CDN with a bunch of features. I'm especially excited for the release of Cloudflare Pub/Sub!
All of the code for the Document Requester app is available here.